科學技術院研究團隊利用人工智能打破音樂本能
音樂通常被稱為通用語言,是所有文化的共同組成部分。那么,盡管文化之間存在巨大的環境差異,“音樂本能”是否可以在某種程度上是共享的?
1 月 16 日,韓國科學技術院物理系教授 Hawoong Jung 領導的研究小組宣布,利用人工神經網絡模型,確定了人腦無需特殊學習即可產生音樂本能的原理。
此前,許多研究人員試圖找出各種不同文化中存在的音樂之間的異同,并試圖理解普遍性的起源。2019 年《科學》雜志上發表的一篇論文揭示,音樂是在所有民族志不同的文化中產生的,并且使用相似的節拍和曲調形式。神經科學家此前還發現,人腦的一個特定部分,即聽覺皮層,負責處理音樂信息。
榮格教授的團隊使用人工神經網絡模型表明,音樂認知功能是在處理從大自然接收到的聽覺信息時自發形成的,而無需學習音樂。研究團隊利用谷歌提供的大規模聲音數據集合AudioSet,教授人工神經網絡學習各種聲音。有趣的是,研究小組發現網絡模型中的某些神經元會選擇性地對音樂做出反應。換句話說,他們觀察到神經元的自發生成,這些神經元對各種其他聲音(例如動物、自然或機器的聲音)反應最小,但對各種形式的音樂(包括器樂和聲樂)表現出高水平的反應。
人工神經網絡模型中的神經元表現出與真實大腦聽覺皮層中的神經元類似的反應行為。例如,人工神經元對被剪成短間隔并重新排列的音樂聲音反應較小。這表明自發產生的音樂選擇性神經元編碼音樂的時間結構。這種屬性并不局限于特定的音樂流派,而是出現在 25 種不同的音樂流派中,包括古典、流行、搖滾、爵士和電子。
<圖1.大腦和人工神經網絡的音樂性圖示(根據論文內容使用DALL·E3 AI創建)>
此外,抑制音樂選擇性神經元的活動被發現會極大地阻礙對其他自然聲音的認知準確性。也就是說,處理音樂信息的神經功能有助于處理其他聲音,而“音樂能力”可能是一種本能,是為了更好地處理來自自然界的聲音而獲得的進化適應的結果。
為這項研究提供建議的 Hawoong Jung 教授表示:“我們的研究結果表明,進化壓力有助于形成不同文化中處理音樂信息的普遍基礎。” 至于這項研究的意義,他解釋道:“我們期待這種人工構建的具有類人音樂性的模型能夠成為人工智能音樂生成、音樂治療和音樂認知研究等各種應用的原創模型。” 他也評論了其局限性,并補充道,“但這項研究并沒有考慮到音樂學習后的發展過程,必須指出的是,這是一項以早期發展中處理音樂信息為基礎的研究。”
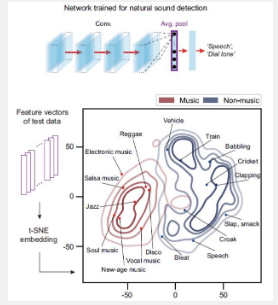
< 圖 2. 學會識別網絡空間中的非音樂自然聲音的人工神經網絡可以區分音樂和非音樂。>
這項研究由第一作者韓國科學技術院物理系(現隸屬:麻省理工學院腦與認知科學系)的 Gwangsu Kim 博士和 Dong-Kyum Kim 博士(現隸屬:IBS)進行,發表在Nature Communications上,標題為,“深度神經網絡中基本音樂檢測器的自發出現”。
這項研究得到了韓國國家研究基金會的支持。
免責聲明:本答案或內容為用戶上傳,不代表本網觀點。其原創性以及文中陳述文字和內容未經本站證實,對本文以及其中全部或者部分內容、文字的真實性、完整性、及時性本站不作任何保證或承諾,請讀者僅作參考,并請自行核實相關內容。 如遇侵權請及時聯系本站刪除。